近日,AI領域掀起了一場關于基準測試結果真實性的風波。爭議的焦點集中在埃隆·馬斯克旗下的xAI公司最新發布的AI模型Grok 3上。一名OpenAI員工對xAI公司公布的Grok 3在AIME 2025基準測試中的表現提出了質疑,認為其測試結果具有誤導性。
xAI公司在其官方博客上發布了一張圖表,展示了Grok 3的兩個版本——Grok 3 Reasoning Beta和Grok 3 mini Reasoning,在AIME 2025基準測試中的卓越表現。盡管AIME作為AI基準測試的有效性受到了一些專家的質疑,但它仍然被廣泛用于評估AI模型的數學能力。這張圖表顯示,Grok 3的兩個版本在AIME 2025上的表現超越了OpenAI當前最強的可用模型o3-mini-high。
然而,OpenAI員工迅速作出回應,在社交媒體平臺上指出xAI的圖表并未包含o3-mini-high在“cons@64”條件下的得分。“cons@64”即允許模型對每個問題嘗試64次,并將出現頻率最高的答案作為最終答案,這種方式通常會顯著提升模型的基準測試分數。因此,如果圖表中省略了這一數據,就可能導致誤解。
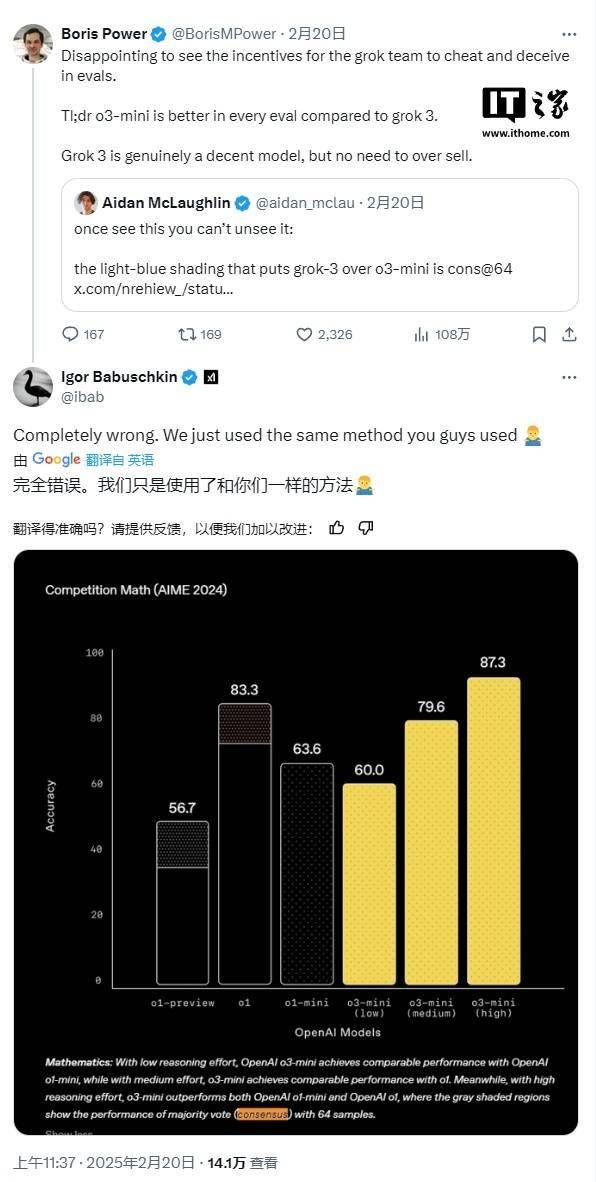
事實上,在AIME 2025的“@1”條件下(即模型首次嘗試的得分),Grok 3 Reasoning Beta和Grok 3 mini Reasoning的得分均低于o3-mini-high。Grok 3 Reasoning Beta的表現也略遜于OpenAI的o1模型在“中等計算”設置下的得分。盡管如此,xAI仍堅持宣傳Grok 3為“世界上最聰明的AI”。
面對質疑,xAI的聯合創始人伊戈爾·巴布什金在社交媒體上進行了辯護,他指出OpenAI過去也曾發布過類似的具有誤導性的基準測試圖表,盡管這些圖表是用于比較OpenAI自身模型的表現。這一回應并未平息爭議,反而進一步加劇了雙方的對立。
在這場爭議中,一位中立的第三方重新繪制了一張更為準確的圖表,揭示了雙方模型在AIME 2025基準測試中的真實表現。這張圖表的出現,為公眾提供了一個更為客觀、全面的視角來審視這場風波。
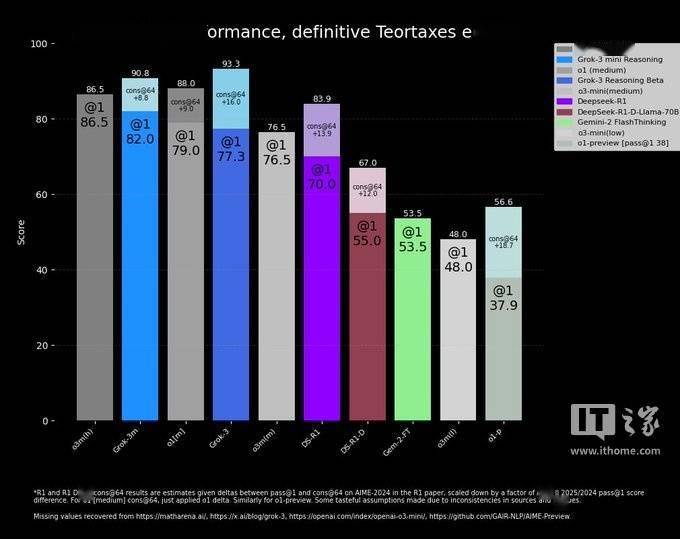
然而,這場風波也暴露出AI基準測試在傳達模型局限性和優勢方面的不足。AI研究員內森·蘭伯特在一篇文章中指出,或許最重要的指標仍然未知:每個模型達到最佳分數所需的計算(和金錢)成本。這一觀點引發了業界的廣泛共鳴,也讓人們開始重新審視AI基準測試的意義和價值。