英偉達(dá)近期震撼發(fā)布了Eagle 2.5視覺(jué)-語(yǔ)言模型,該模型專為大規(guī)模視頻與圖像的處理而設(shè)計(jì),展現(xiàn)了卓越的多模態(tài)學(xué)習(xí)能力。在復(fù)雜的視覺(jué)與語(yǔ)言融合任務(wù)中,Eagle 2.5憑借其出色的性能,成為了業(yè)界的焦點(diǎn)。
Eagle 2.5不僅擅長(zhǎng)解析高分辨率圖像,更在處理長(zhǎng)視頻序列時(shí)游刃有余。盡管其參數(shù)規(guī)模僅為80億,但在Video-MME基準(zhǔn)測(cè)試中,Eagle 2.5以72.4%的高分脫穎而出,這一成績(jī)令人矚目,甚至與參數(shù)量遠(yuǎn)超其上的Qwen2.5-VL-720億和InternVL2.5-780億等模型相媲美。
Eagle 2.5的成功背后,兩大創(chuàng)新訓(xùn)練策略功不可沒(méi):信息優(yōu)先采樣與漸進(jìn)式后訓(xùn)練。信息優(yōu)先采樣策略通過(guò)兩項(xiàng)獨(dú)特技術(shù),進(jìn)一步優(yōu)化了模型的訓(xùn)練過(guò)程。
首先,圖像區(qū)域保留(IAP)技術(shù)確保了超過(guò)60%的原始圖像區(qū)域得以保留,有效避免了寬高比失真,從而保證了圖像的完整性和真實(shí)性。其次,自動(dòng)降級(jí)采樣(ADS)技術(shù)根據(jù)上下文長(zhǎng)度,智能地平衡視覺(jué)與文本輸入,既保證了文本的完整性,又優(yōu)化了視覺(jué)細(xì)節(jié)的呈現(xiàn),使得模型在處理復(fù)雜場(chǎng)景時(shí)更加游刃有余。
而漸進(jìn)式后訓(xùn)練策略,則是通過(guò)逐步擴(kuò)展模型的上下文窗口,從32K到128K token,使模型能夠靈活應(yīng)對(duì)不同長(zhǎng)度的輸入。這一策略不僅增強(qiáng)了模型的泛化能力,還避免了模型對(duì)單一上下文范圍的過(guò)擬合,確保了模型在各種情況下的穩(wěn)定性能。
為了訓(xùn)練Eagle 2.5,英偉達(dá)整合了豐富的開(kāi)源資源與定制數(shù)據(jù)集Eagle-Video-110K。該數(shù)據(jù)集專為理解長(zhǎng)視頻而設(shè)計(jì),采用了獨(dú)特的雙重標(biāo)注方式。自上而下的方法,通過(guò)故事級(jí)分割,結(jié)合人類標(biāo)注的章節(jié)元數(shù)據(jù)和GPT-4生成的密集描述,為模型提供了宏觀的敘事結(jié)構(gòu)。而自下而上的方法,則利用GPT-4為短片段生成問(wèn)答對(duì),捕捉時(shí)空細(xì)節(jié),為模型提供了微觀的信息補(bǔ)充。
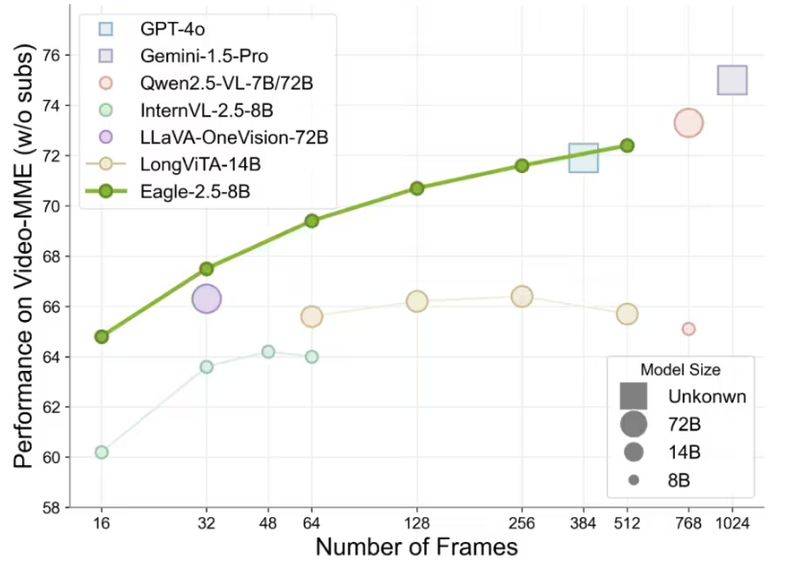
數(shù)據(jù)集還通過(guò)余弦相似度篩選,確保了數(shù)據(jù)的多樣性和非冗余性。這一舉措不僅提升了數(shù)據(jù)的敘事連貫性和細(xì)粒度標(biāo)注質(zhì)量,還顯著增強(qiáng)了模型在高幀數(shù)(128幀)任務(wù)中的表現(xiàn)。Eagle 2.5在處理長(zhǎng)視頻和復(fù)雜圖像時(shí)展現(xiàn)出的卓越能力,正是得益于這一精心設(shè)計(jì)的訓(xùn)練數(shù)據(jù)管道。