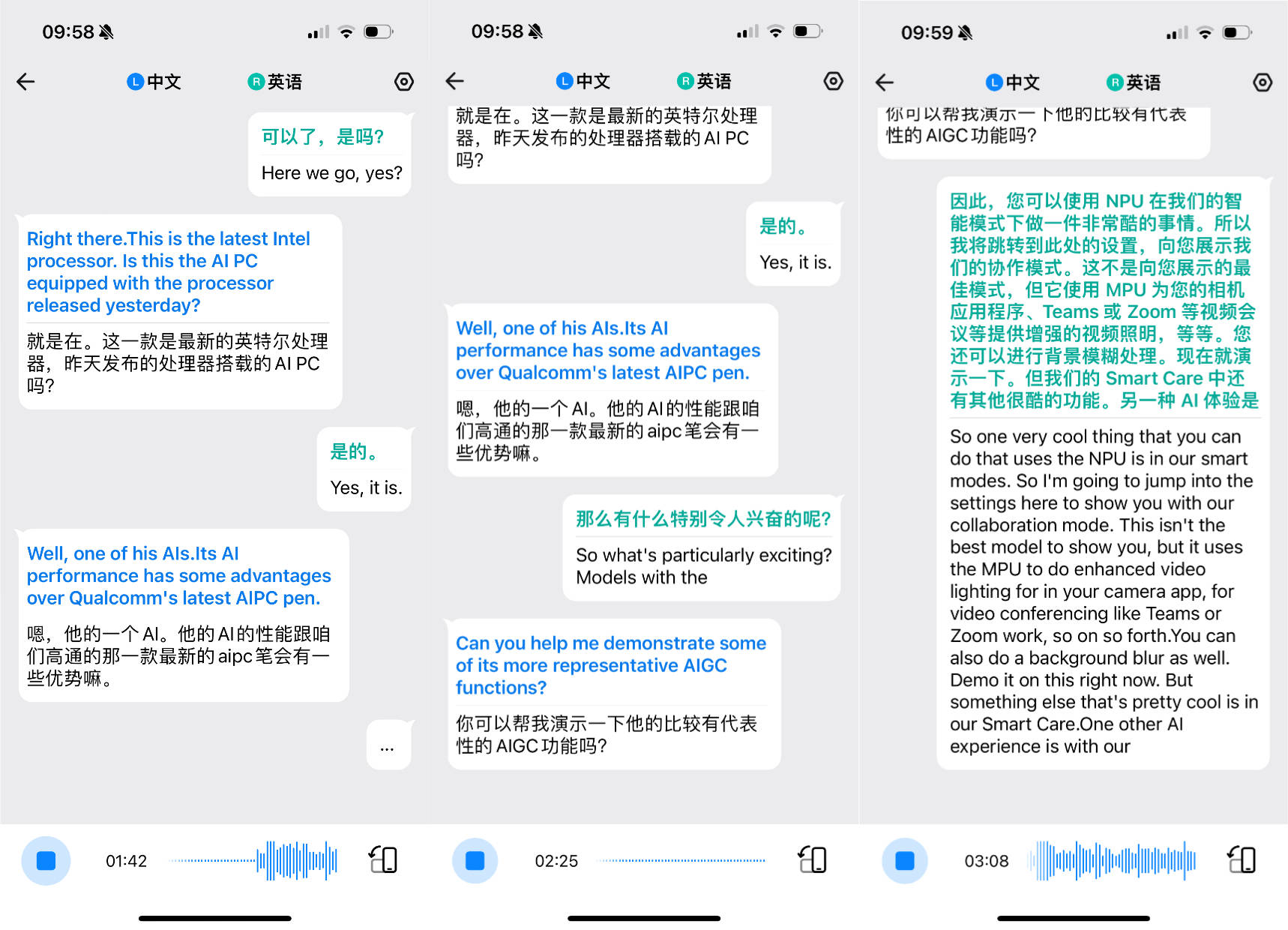
在2025年的初夏,全球的目光聚焦于日本,共同見證了2025世博會的盛大開幕。盡管這屆世博會因籌備時間緊迫而在網(wǎng)絡(luò)上引發(fā)了不少爭議,但它無疑為觀眾帶來了諸多意想不到的樂趣。尤其是日本媒體在采訪中所使用的翻譯設(shè)備,因誤將“有看到什么厲害的東西嗎?”翻譯為“有什么了不起的?”,成為了網(wǎng)絡(luò)上廣為流傳的一段佳話。
盡管這只是翻譯設(shè)備因上下文理解不足而導(dǎo)致的小誤會,但從用戶的角度來看,翻譯設(shè)備作為跨語言交流的橋梁,確實需要一個更為清晰明確的能力邊界定義。正如汽車的輔助駕駛和自動駕駛有著明確的分類一樣,翻譯設(shè)備也迫切需要一個類似的評級系統(tǒng)。
回顧過去,那些被90后學(xué)生當(dāng)作掌機(jī)來玩的電子詞典,只能被歸類為L1級別的翻譯設(shè)備。這類設(shè)備本質(zhì)上就是一個數(shù)字化的、支持快速搜索和朗讀功能的字典,其翻譯引擎基于傳統(tǒng)的文本引擎,只能進(jìn)行最基本的詞對詞翻譯。即使你輸入一整句話,L1翻譯設(shè)備也只能逐詞翻譯,導(dǎo)致諸如將“白花了”錯誤地翻譯為“White Flowers”這樣的笑話頻出。
L2級別的翻譯設(shè)備在原理上與L1相似,同樣是基于詞對詞的映射翻譯。但L2設(shè)備增加了語音識別模塊,可以自動將語音轉(zhuǎn)寫成文字,省去了用戶手動輸入的麻煩。后來,部分品牌還將L2翻譯技術(shù)集成到了耳機(jī)中,但即便是“翻譯耳機(jī)”,也未能改變單向翻譯的邏輯,即一人說話,另一人只能等待翻譯完成。
然而,L3級別的翻譯技術(shù)卻是一個分水嶺。由于引入了AI大模型,L3翻譯設(shè)備具備了理解語義和上下文聯(lián)系的能力。同時,多模態(tài)模型等技術(shù)也顯著加快了語音翻譯的速度。在體驗上,L3翻譯設(shè)備借助矢量降噪技術(shù),實現(xiàn)了雙向同傳的突破,成為了目前體驗最好的翻譯模式。遺憾的是,目前谷歌、蘋果等企業(yè)仍停留在L2級別。
不同AI翻譯模型的能力千差萬別,有些品牌能做到語義、情緒的精準(zhǔn)傳達(dá),而有些則只能提供“僅供參考”的翻譯結(jié)果。開頭提到的“有什么了不起的?”便是一個典型的翻譯錯誤案例。
但并非沒有值得稱贊的翻譯案例。前段時間,時空壺再次登上《新聞聯(lián)播》,成為了AI同傳技術(shù)的代表,也是目前唯一一款達(dá)到L3水準(zhǔn)的AI同傳耳機(jī)。

在《新聞聯(lián)播》中,記者用近4分鐘的時間向外界展示了時空壺如何利用AI技術(shù)在翻譯領(lǐng)域取得的突破。這已經(jīng)是時空壺在2025年內(nèi)第二次登上央視舞臺。作為成立近十年的“老企業(yè)”,時空壺是如何在AI時代找到自己的競爭力的呢?
在雷科技看來,時空壺之所以能在短時間內(nèi)坐上翻譯設(shè)備的頭把交椅,并將領(lǐng)先優(yōu)勢延續(xù)了近十年,這背后離不開其對翻譯軟硬件技術(shù)的深度探索。時空壺突破了雙向同傳的技術(shù)限制,率先邁入了L3翻譯的階段,并在場景拓展、AI大模型升級等方面實現(xiàn)了飛躍,與傳統(tǒng)的L2翻譯設(shè)備拉開了體驗的代差。
傳統(tǒng)的L2翻譯設(shè)備,無論是手持的翻譯機(jī)還是佩戴的翻譯耳機(jī),都無法擺脫L1翻譯效率低、錯誤率高的問題。即使從文字輸入轉(zhuǎn)變?yōu)檎Z音輸入和TTS語音輸出,其算法仍然基于老舊的L1翻譯模式。這導(dǎo)致L2時代的翻譯耳機(jī)需要極長的翻譯時間,只能實現(xiàn)“偽同傳”。
而且,為了控制成本,這些L2翻譯耳機(jī)通常基于市面上成熟的TWS公模開發(fā)。但這些公模TWS顯然不會針對翻譯耳機(jī)特殊的工作環(huán)境(背景噪聲大、對話距離近、佩戴時間長、人聲降噪要求高)進(jìn)行優(yōu)化。以雷科技參加CES等海外展會的經(jīng)歷為例,普通的翻譯耳機(jī)幾乎無法準(zhǔn)確識別雙方的對話內(nèi)容,更不用說進(jìn)行準(zhǔn)確的翻譯了。
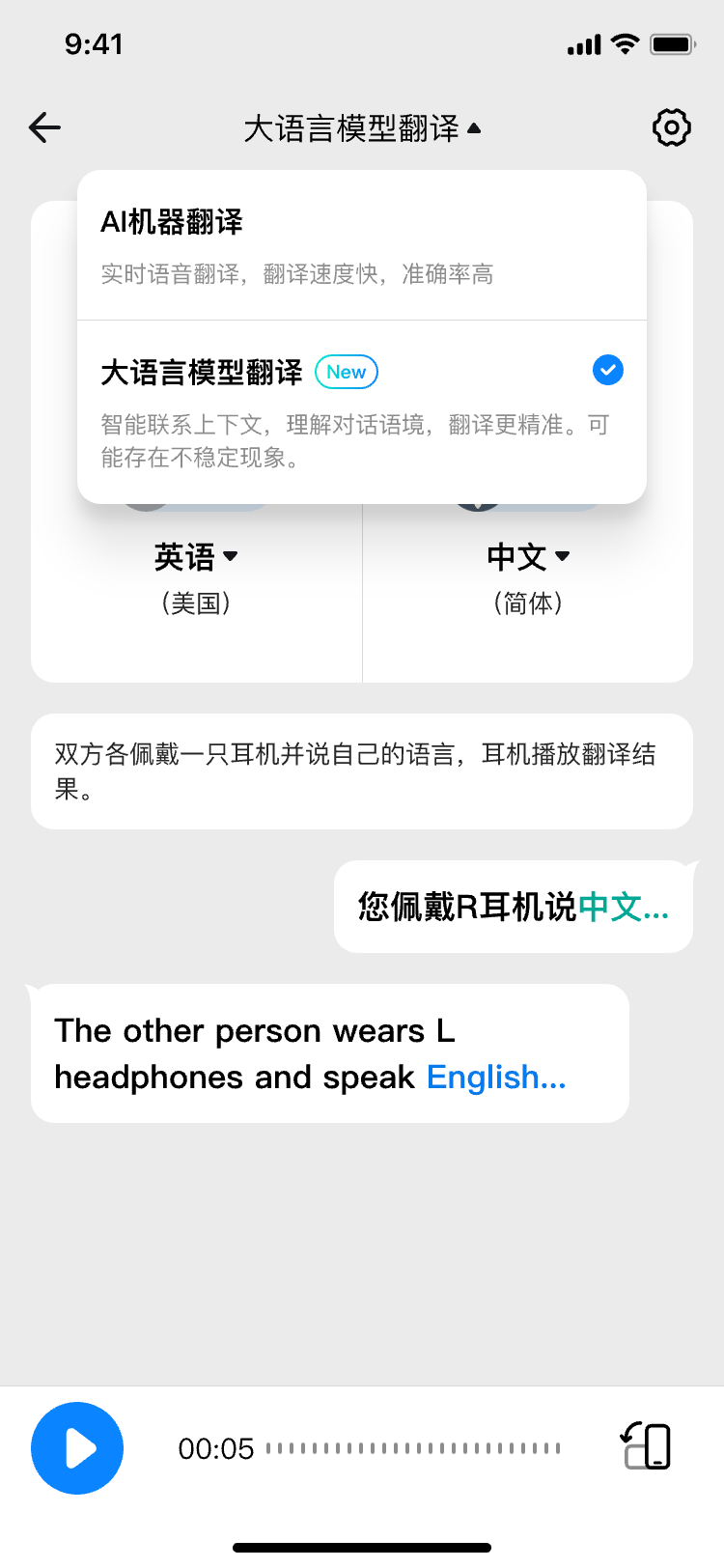
其中,對用戶體驗影響最大的便是L2翻譯耳機(jī)的“偽同傳”問題。在參加CES、MWC等海外展會時,雷科技通常都帶有采訪任務(wù)。為了保證雙方發(fā)言的準(zhǔn)確性,我們在采訪時通常都會說各自的母語,再由翻譯設(shè)備進(jìn)行翻譯。然而,L2翻譯耳機(jī)的單向同傳短板便暴露無遺。由于翻譯耳機(jī)一次只能處理一個人的說話內(nèi)容,無論是從現(xiàn)場收音質(zhì)量還是模型翻譯質(zhì)量的角度來看,使用L2翻譯耳機(jī)進(jìn)行采訪都會嚴(yán)重影響雙方的交流效率。
相比之下,L3翻譯的雙向同傳模式允許對話雙方各說各話,各自的同傳會將譯文同時輸出給對方,省去了單向翻譯中的等待步驟。人類的交流天生是雙向的,因此雙向同傳模式更符合人類母語交流的習(xí)慣。
然而,要實現(xiàn)雙向同傳并非易事。首先,在面對面交流中,翻譯設(shè)備難以區(qū)分發(fā)言人。在嘈雜的展館中,使用翻譯耳機(jī)時必須足夠大聲,但傳統(tǒng)翻譯耳機(jī)的收音模式未經(jīng)優(yōu)化,很容易將雙方的聲音都捕捉到,導(dǎo)致翻譯混亂。
傳統(tǒng)L2翻譯耳機(jī)缺乏上下文聯(lián)系的能力,本身也不適合采訪這種深度、長時間、貫穿上下文的對話模式。即使準(zhǔn)備兩套翻譯設(shè)備,也只會帶來雙倍甚至更多的麻煩。這也是市面上大多數(shù)翻譯設(shè)備不提供雙向翻譯模式的根本原因。

但時空壺卻迎難而上,憑借雙向同傳及其背后的技術(shù)挑戰(zhàn),在眾多翻譯設(shè)備中脫穎而出。時空壺利用軟硬合一的矢量降噪技術(shù)優(yōu)化了收音效果,為雙向翻譯的語音識別準(zhǔn)確率打下了基礎(chǔ)。2021年,時空壺發(fā)布了第一代雙向同傳耳機(jī)W3,標(biāo)志著行業(yè)在雙向翻譯(L3翻譯)中取得了從零到一的突破。
作為W3的“繼任者”,W4 Pro基于W3的成功經(jīng)驗,針對W3的體驗短板做出了多項改進(jìn)。在IFA期間,雷科技發(fā)現(xiàn)W4 Pro的長桿耳機(jī)造型、每邊三麥克風(fēng)陣列以及時空壺的軟件降噪技術(shù),不僅可以在嘈雜環(huán)境中準(zhǔn)確捕捉對話的聲音,還能精確地將對話雙方的聲音分離,確保每只耳機(jī)“只聽一人講話”。這一矢量降噪技術(shù)從源頭確保了翻譯原聲的準(zhǔn)確度。
在翻譯環(huán)節(jié),時空壺也充分開發(fā)、整合了AI大模型的能力。在時空壺App中,W4 Pro翻譯耳機(jī)的用戶可以隨時切換傳統(tǒng)的AI機(jī)器翻譯(NMT模式)和大語言模型翻譯(LLM翻譯模式)。得益于大模型的加入,時空壺的雙向翻譯具備了對上下文的理解能力,可以根據(jù)歷史對話排除不符合語境的多音字、多義詞分支,獲得更準(zhǔn)確的翻譯效果。
以大語言模型驅(qū)動的翻譯模式為例,它能夠準(zhǔn)確識別出“手沖咖啡”中的沖洗和沖泡,并給出正確的譯文,避免“直譯”帶來的誤會。大語言模型的加入還讓時空壺具備了“過濾”能力,可以過濾掉用戶重復(fù)的語氣輔助詞和因緊張、口吃而重復(fù)說出的詞。
在功能拓展方面,W4 Pro也沿著雙向同傳的路徑,拓展出了電話翻譯、音視頻翻譯等場景,帶來了“全場景翻譯”的能力。而最重要的是,大語言模型對翻譯的“提速”。傳統(tǒng)的NMT(神經(jīng)機(jī)器翻譯)模式必須等句子說完才能開始翻譯流程,這是雙向同傳真正的“卡脖子”之處。但大語言模型的加入讓時空壺具備了理解上下文的能力,能夠準(zhǔn)確“預(yù)判”雙方的含義和原句的完成進(jìn)度,像真人同傳那樣進(jìn)行“開放式翻譯”,在句子說完之前就輸出譯文,并根據(jù)原文的語義及時調(diào)整輸出的譯文。