meta公司近期在人工智能領(lǐng)域邁出了重要一步,推出了名為meta Motivo的創(chuàng)新模型。該模型專注于控制類人數(shù)字智能體的動作,旨在為用戶帶來更加沉浸式的元宇宙體驗。
在周四的發(fā)布會上,meta不僅展示了meta Motivo,還介紹了其他兩項AI工具:大型概念模型LCM和視頻水印工具Video Seal。這些舉措再次表明了meta對于AI、增強現(xiàn)實(AR)以及元宇宙技術(shù)的持續(xù)投資與承諾。
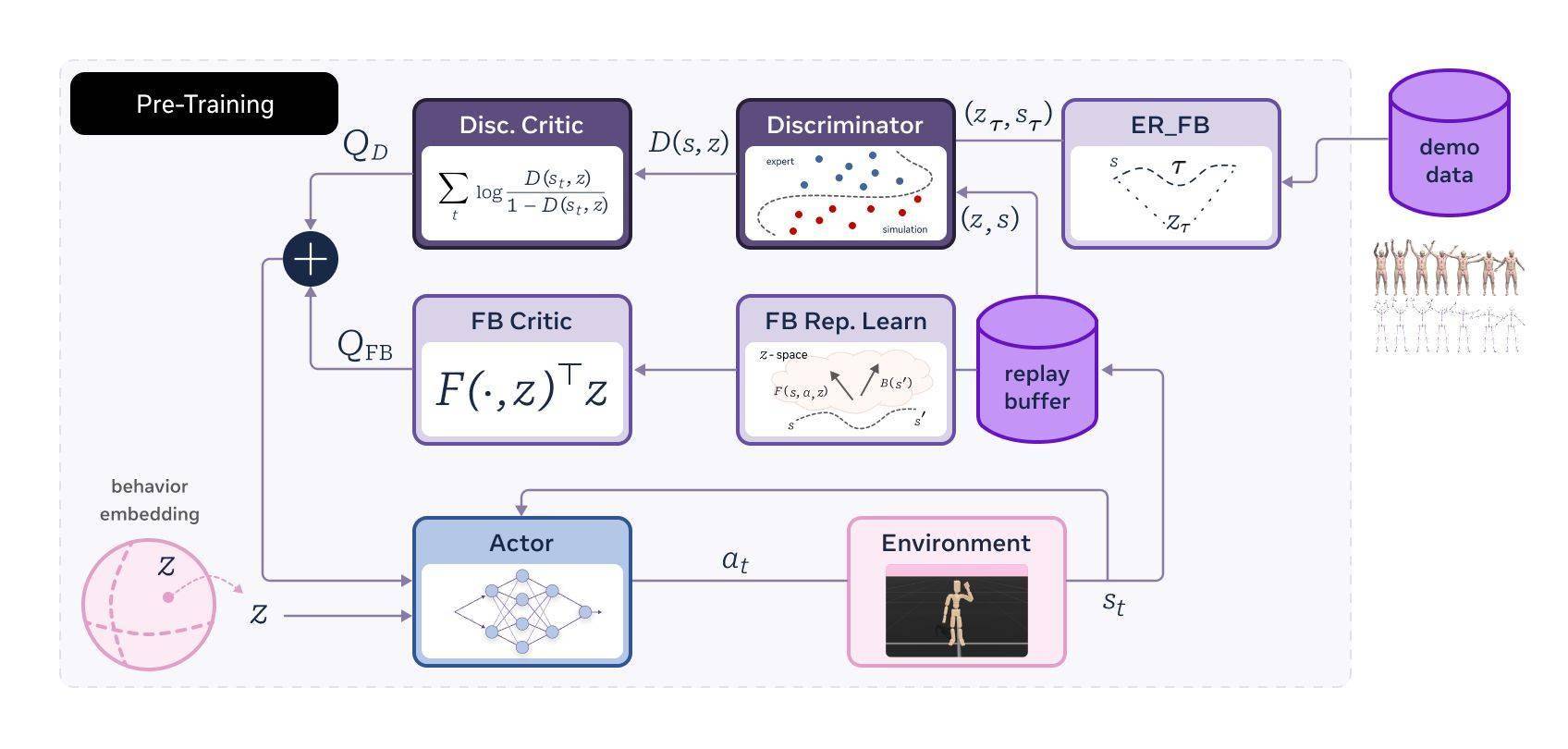
meta Motivo是一個基于行為的基礎(chǔ)模型,它的訓練過程充滿了技術(shù)含量。模型在Mujoco模擬器中得到了充分的鍛煉,使用了AMASS動作捕捉數(shù)據(jù)集的一個子集,并結(jié)合了3000萬個在線交互樣本。通過一種新型的無監(jiān)督強化學習算法,meta Motivo能夠預訓練并控制復雜虛擬人形智能體的運動。

在訓練過程中,meta Motivo采用了一種名為FB-CPR的算法。這種算法能夠利用未標記的動作數(shù)據(jù)集,不僅保留了零樣本推理能力,還能將無監(jiān)督強化學習引導至學習類似人類的行為。這一技術(shù)創(chuàng)新使得meta Motivo在動作軌跡跟蹤、姿勢到達以及獎勵優(yōu)化等任務上,展現(xiàn)出了更加接近人類的行為。
值得注意的是,盡管meta Motivo沒有經(jīng)過任何特定任務的顯式訓練,但在預訓練過程中,它在多個任務上的性能都得到了顯著提升。例如,在動作軌跡跟蹤方面,它能夠準確地進行側(cè)手翻等動作;在姿勢到達方面,它能夠呈現(xiàn)出如阿拉貝斯克舞姿般的優(yōu)雅姿態(tài);在獎勵優(yōu)化方面,它的跑步動作也更加自然流暢。
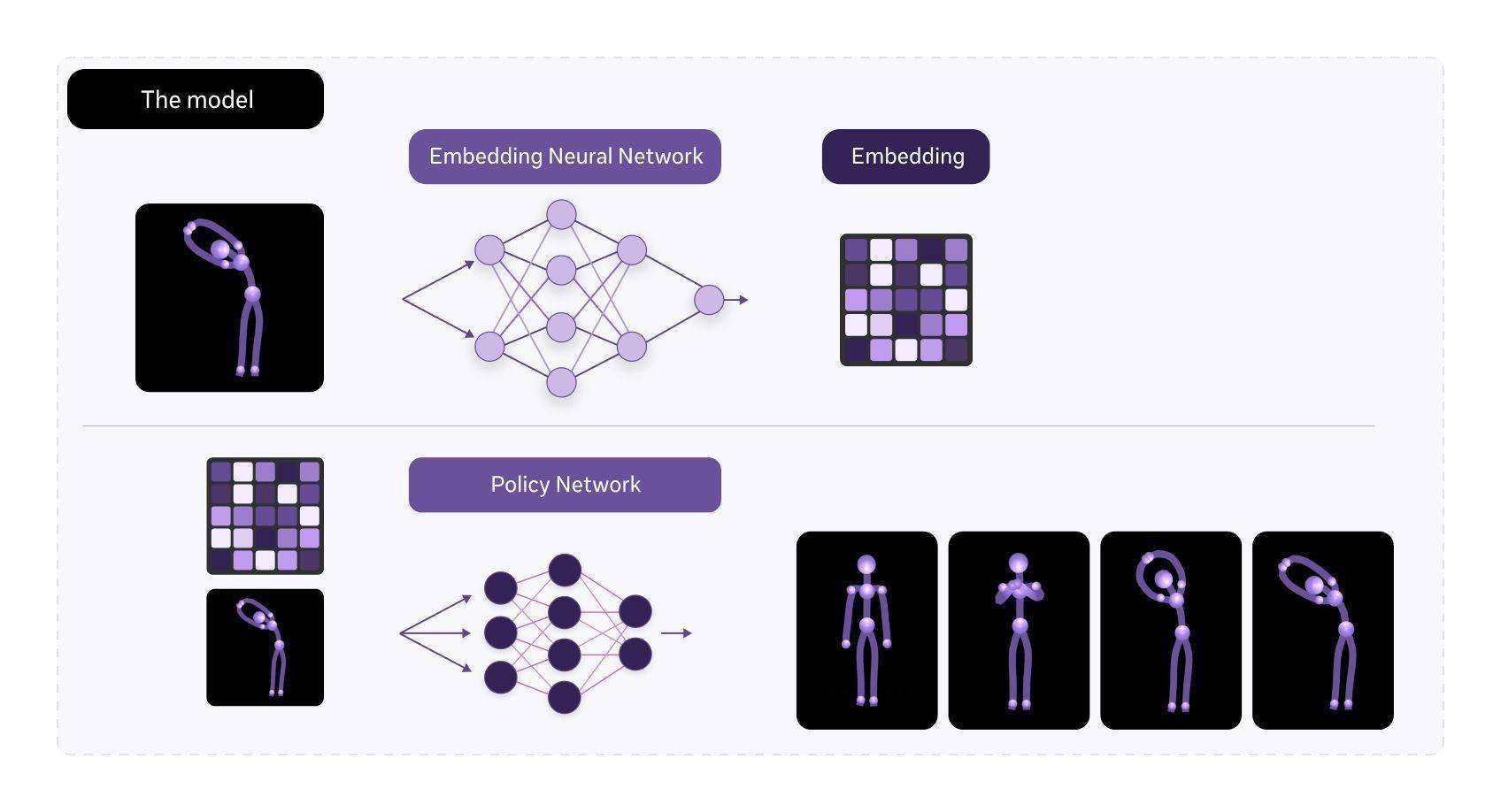
meta Motivo的成功離不開其關(guān)鍵技術(shù)創(chuàng)新——學習表示。這種表示能夠?qū)顟B(tài)、動作和獎勵嵌入到相同的潛在空間中,使得meta Motivo能夠解決各種全身控制任務。無論是運動跟蹤、目標姿態(tài)到達還是獎勵優(yōu)化,meta Motivo都無需任何額外的訓練或規(guī)劃,就能展現(xiàn)出出色的表現(xiàn)。
meta的這一系列舉措無疑將推動元宇宙技術(shù)的發(fā)展,為用戶帶來更加真實、沉浸的虛擬體驗。隨著meta在AI領(lǐng)域的不斷探索和投入,我們有理由相信,未來的元宇宙將更加豐富多彩、充滿無限可能。